


 智能体助手部署
智能体助手部署
创建时间:2025-10-24 最近修改时间:2025-10-24
#1. 智能体助手部署
#1.1 前提条件
已在 K8s 上部署 DeepFlow 企业版(6.6 或更高版本),可参考以下文档。如使用其他版本,请通过工单沟通。
#1.1.1 部署参数
通过修改 values-custom.yaml 启用 dfWebAi、dfAnalyze 组件,可以启用智能体助手页面。同时,可以通过配置环境变量 env 来选择和配置使用的大模型。添加如下内容:
dfWebAi:
enabled: true # 默认为false
dfAnalyze:
enabled: true # 默认为false
env:
# 环境变量配置
1
2
3
4
5
6
2
3
4
5
6
#1.1.2 接入模型
以 DeepSeek 为例,添加以下配置。定制化模型的参数请通过工单进行沟通
dfAnalyze:
env:
ENV_AI_TYPE: deepseek // 大模型的名称
DEEPSEEK_API_KEY: "xxx" // DeepSeek 的 ApiKey
DEEPSEEK_BASE_URL: "xxx" // DeepSeek的URL,根据客户实际环境地址设置
DEEPSEEK_MODEL: "" // 可不设置此项,默认是R1,可选的有 'deepseek-reasoner'(R1)和'deepseek-chat'(V3)
DEEPSEEK_MAX_TOKENS: "" //可不设置此项,默认值:8192,若不确定具体值,请勿随意修改
1
2
3
4
5
6
7
2
3
4
5
6
7
#1.1.2.1 部署智能体助手组件:
/usr/local/deepflow/bin/deepflow-deploy -s
1
#1.1.2.2 卸载智能体助手组件:
/usr/local/deepflow/bin/deepflow-deploy -es
1
#2. DeepFlow Ai-web 组件部署
#2.1 架构图
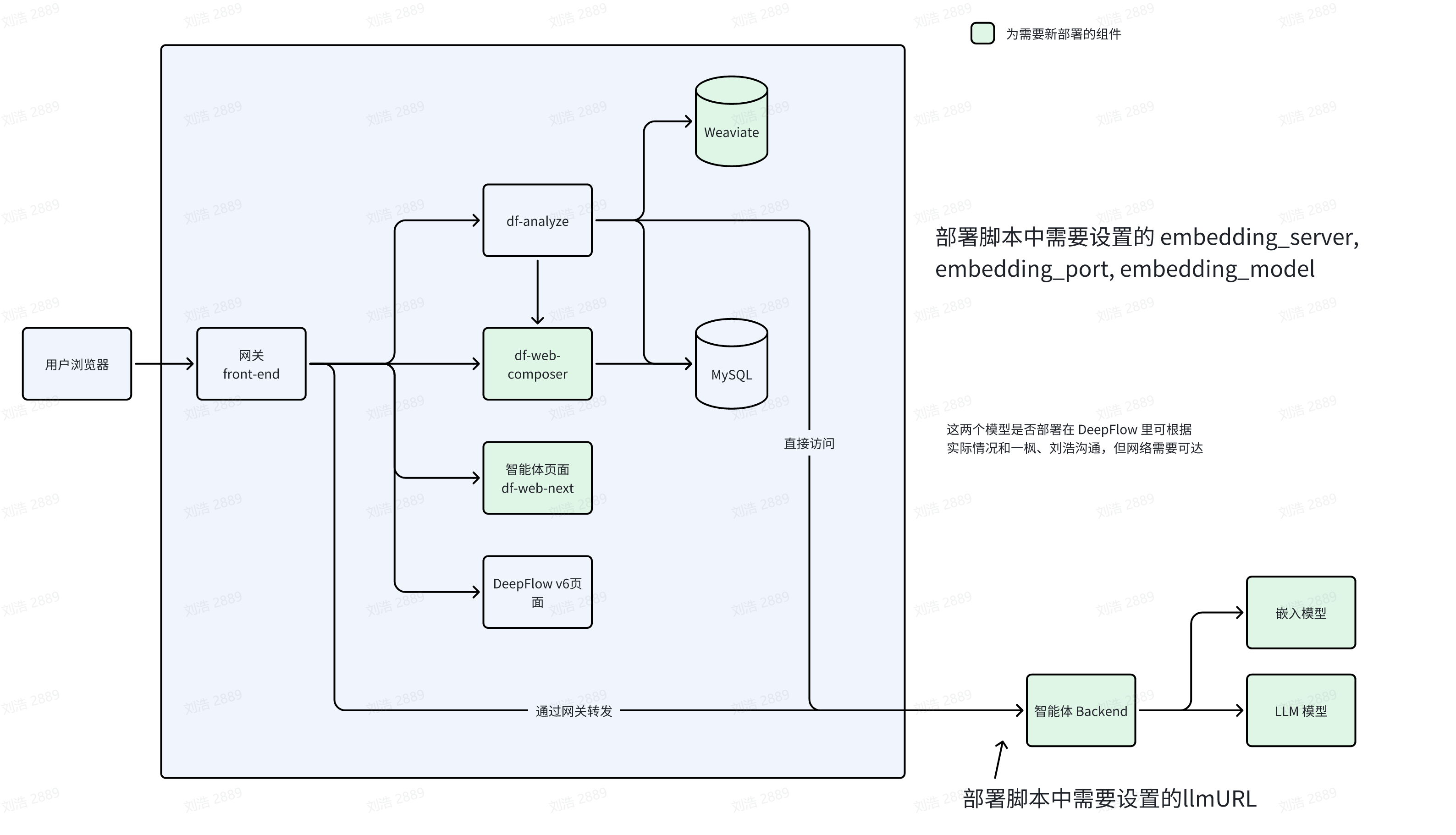
label
注意:
- 智能体的「处置方案」和「场景编排」这两个功能需要依赖嵌入模型。注意嵌入模型和 LLM 模型不是同一个模型
- LLM 模型需要首先对接到智能体 Backend 中,在 df-analyze、
- LLM 的部署中需要的 llmurl 都是指经过智能体 Backend 暴露出来的端口
#2.1.1 部署方案:
前提条件:
- v6.6 环境必须更新 patch 到 46 以上
- openebs必须安装,可通过如下命令检查
kubectl get pod -n openebs
有如下返回即表示正常
[root@iZ2ze2qiflhjmrs95gs5b8Z df-ai-deploy]# kubectl get pod -nopenebs
NAME READY STATUS RESTARTS AGE
openebs-localpv-provisioner-796d94dcc7-h76sx 1/1 Running 4 (102m ago) 4d8h
openebs-ndm-brrt2 1/1 Running 3 (102m ago) 4d8h
openebs-ndm-operator-68d76d5674-th5sw 1/1 Running 3 (102m ago) 4d8h
1
2
3
4
5
6
7
2
3
4
5
6
7
#2.1.1.1 下载 DeepFlow 智能体组件 chart 包和部署方案
- 文件位置: https://publicshare-unsafe.oss-cn-beijing.aliyuncs.com/v6.6/df-ai-deploy.tar.gz
#找个目录用于存放DeepFlow 智能体组件的chart
cd xxxx
tar -xzf df-ai-deploy.tar.gz
cat df-ai-deploy/charts/value-clustom.yaml
global:
imagePullSecrets: [] #实际环境记得修改
mysqlByProxysql: true #实际环境记得修改
image:
repository: __FIXME_REGISTRY_URL__ #仓库地址 #实际环境记得修改
password:
mysql: YSDeepFlow@3q302 #实际环境记得修改
redis: YSDeepFlow@3q302 #实际环境记得修改
llmUrl: "http://llm_server" # 需要front-end以及composer组件访问该地址
dfWebComposer:
df-web-composer_tag: __FIXME_IMAGE_TAG__ #实际环境记得修改
dfWebNext:
df-web-next_tag: __FIXME_IMAGE_TAG__ #实际环境记得修改
frontEnd:
apientry_tag: __FIXME_IMAGE_TAG__ #实际环境记得修改0.
dfAnalyze:
df-analyze_tag: __FIXME_IMAGE_TAG__ #实际环境记得修改
embeddingServer: "" #从研发处获取
embeddingPort: "" #从研发处获取
embeddingModelName: "" #从研发处获取
# weaviate storage 配置
storage:
size: 32Gi
storageClassName: "openebs-hostpath"
# 自行将相关组件的镜像上传到DeepFlow镜像仓库,所有镜像的版本找`研发`获取
# 部署
cd df-ai-deploy
bash bin/df-ai-deploy -i
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
#2.1.1.2 注意事项
- 每次打patch/通过ISO升级后,front-end的配置会还原如需继续使用智能体请执行 bash bin/df-ai-deploy -uf
- 更新智能体组件,修改df-ai-deploy/charts/value-clustom.yaml 部署参数后执行 bash bin/df-ai-deploy -u
- 如之前部署过智能体,请先卸载。 helm uninstall xxx -ndeepflow
- 本脚本对6.6的deepflow的部署改动只有front-end组件,其余组件均是新增,如需卸载并还原6.6配置,请执行 bash bin/df-ai-deploy -e deepflow-deploy -uo front-end
- 目前仍需手动上传镜像到仓库,后面会将镜像包打入合集(脚本仅适配自建仓库)
#3. DeepFlow 智能体组件部署
前提条件:
- GPU 服务器已经安装好驱动 检查驱动
英伟达:nvidia-smi
昇腾:npu-smi info
1
2
2
主要是部署以下三个组件:
- DeepFlow 智能体引擎部署 (如有 GPU 服务器则部署在 GPU 服务器上,如用客户大模型,可部署在 DeepFlow 集群 or 单独虚拟机部署)
- DeepFlow 推理大模型部署(必须 GPU 推理)
- DeepFlow 嵌入大模型部署(推荐 CPU 推理)
#3.1 软件包地址
路径 : https://publicshare-unsafe.oss-cn-beijing.aliyuncs.com/llm/
文件list
DeepFlow-LLM-Embeddings.zip
DeepFlow-LLM.zip
deepflow-engine-arm.tar
deepflow-engine-x86.tar
deepflow-vllm.tar
docker26-centos-x86.tar.gz
docker26-centos-arm.tar.gz
embeddings-server-x86.tar
embeddings-server-arm.tar
ascend/ascend.zip
ascend/docker-arm64.zip
ascend/vllm-ascend-v0.9.2rc2-fixed.tar
ascend/run-docker-vllm-ascend.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
#3.1.1 运行智能体引擎
docker run -d --name deepflow-engine -p 8080:8080 -p 8088:8088 -p 8081:8081 -e OPENAI_API_HOST="http://10.1.23.86:8000" -e OPENAI_API_PATH="/v1/chat/completions" -e OPENAI_API_KEY="sk-yunshan-networks-3302" --restart unless-stopped hub.deepflow.yunshan.net/dev/deepflow-engine:release-general
# 挂载的环境变量需要根据实际环境自行去改
1
2
2
#3.1.2 运行嵌入大模型
docker load -i embeddings-server-x86.tar
docker load -i embeddings-server-arm.tar
unzip DeepFlow-LLM-Embeddings.zip -d /models/
docker run -d -p 8001:8001 --restart unless-stopped -v /models:/models --name deepflow-vllm-embeddings -e MODEL_NAME="/models/DeepFlow-LLM-Embeddings" hub.deepflow.yunshan.net/dev/embeddings-server:dev
1
2
3
4
2
3
4
#3.1.2.1 测试嵌入的脚本
#!/bin/bash
OPT=$1
if [[ "$OPT" == "-h" || "OPT" == "--help" ]]; then
echo "Usage: $0 \"<question>\""
exit 0
fi
REQUEST=$1
if [[ -z "$REQUEST" ]]; then
REQUEST="你好"
fi
MODEL_SERVER=localhost
PORT=8001
API_KEY="sk-yunshan-networks-3302"
MODEL_NAME="/models/DeepFlow-LLM-Embeddings"
request_api()
{
curl -k -X POST "http://$MODEL_SERVER:$PORT/v1/embeddings" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" -d "{
\"model\": \"$MODEL_NAME\",
\"input\": \"$REQUEST\"
}"
}
request_api
bash embeddings_test.sh hello
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#3.1.3 运行推理大模型
#3.1.3.1 NVIDIA
目前部署推理大模型支持的显卡型号系列为 H20,A10
docker load -i deepflow-vllm.tar
unzip DeepFlow-LLM.zip -d models/
docker run -d --network host --runtime=nvidia --restart unless-stopped --gpus all --shm-size=16g -v /models:/models --name deepflow-vllm dfcloud-image-registry-vpc.cn-beijing.cr.aliyuncs.com/public/deepflow-vllm:v0.8.5.post1
1
2
3
4
2
3
4
#3.1.3.2 Ascend
目前部署推理大模型支持的显卡型号系列为 910B
docker load -i vllm-ascend.tar
# 推理运行模型
export IMAGE=quay.io/ascend/vllm-ascend:v0.9.0rc2-fixed
docker run -d \
--name vllm-ascend \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 800:800 \
-v /var/lib/docker/deepflow:/mnt \
-e VLLM_USE_V1=1 \
-e VLLM_USE_MODELSCOPE=True \
-e PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256 \
--restart=unless-stopped $IMAGE \
vllm serve /mnt/DeepFlow-LLM --tensor-parallel-size 2 --max-model-len 16384 --gpu-memory-utilization 0.9 --served-model-name deepflow-ai/DeepFlow-LLM --api-key sk-yunshan-networks-3302 --port 800
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24